
Does anyone really know? You will often hear people talk about “the Google algorithm”, which is an overly simplified way to think about it. The truth is that Google uses a multitude of algorithms, combined with AI and human input in order to attempt to serve us with the best, most relevant results for each query.

These algorithms are largely unknown, very complex and would probably not make any sense to most people. Let’s take a quick look at what we can be fairly certain that Google uses:
- “Spiders” – Are computerized web crawlers (bots) that visit pages and collects data, especially about links and keywords
- Algorithms – They analyze and organize the data, based on a set of principles
- Knowledge graph – A huge database of facts, entities and more
- DeepMind – Google’s AI, which uses machine-learning and an artificial neural network in order to solve problems, play games and more
- Word vectors – An AI method of establishing relevance between words
- RankBrain – Presumably some combination of DeepMind, word vectors and more…?
- Human ratings – Once the machines have done their part, humans rate the results
Now let’s move on to what we do know. Luckily, senior Google ranking engineer Paul Haahr recently held a talk at the search marketing conference (yes, that’s a real thing) SMX West 2016 at the end of March, entitled: “How Google Works: A Google Ranking Engineer’s Story.” You can watch the whole thing here:
In this article, I will break down the information he gives, along with a lot of additional information from other sources, in a way that hopefully makes some sense – and is of value to your SEO efforts.
“We’re going more and more into a world where search is being thought of as an assistant to all parts of your life.”
Emerging trends in online search
Paul starts off by saying that the trend in search is going towards mobile. Right now, the searches are divided roughly equally between mobile and stationary devices, but mobile search is growing at an incredibly fast pace.

This means that, in order to rank well, websites need to be mobile-friendly, user-friendly and fast. People on the go want quick results, they do less typing (in favor voice-based search) and their physical location plays a bigger role.
The second big trend is that additional features are becoming more prevalent. You could say that features are all of the things besides the search itself. This includes (but is not limited to) the items in one of Paul’s slides:
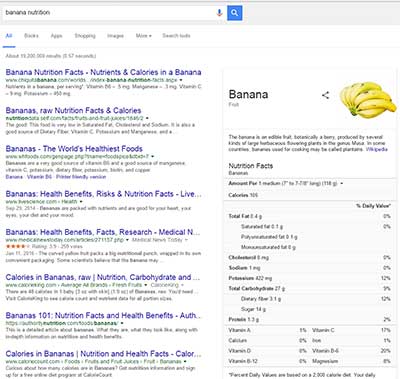
- Spelling suggestions
- Autocomplete
- Related searches
- Related questions
- Calculator
- Knowledge graph
- Answers
- Featured snippets
- Maps
- Images
- Videos
- In-depth articles
- Movie showtimes
- Sport scores
- Weather
- Flight status
- Package tracking
- …
Before getting in to the nitty-gritty of how search works, Paul points out that he doesn’t really know much about Google ads and, in fact, has been told not to think about the paid ads or clicks while developing the search engine.
“Don’t think about ads, don’t think about the effect on revenue – just think about helping the user.”
When Google was in its infancy, it wasn’t much more than the 10 blue links in the results. They are still there, along with ads and features. The questions Google must ask itself to list these links are:
- What documents do we show?
- What order do we show them in?
This is determined by a complex journey called the life of a query – and there are two major stages to it. One takes place before a user inputs a query and one takes place afterwards.

The life of a query
Before the query, Google’s spiders crawl the web, they analyze the crawled pages in order to extract links, render the content and annotate semantics. Lastly, an index of the results is built. In the early days, it was almost entirely focused on links, and a page was rated higher the more incoming links it had.
Now, semantic analysis and annotation is a much larger part of the process. It renders the contents in order to “see” the page the way that users do, and has gotten much better at understanding aspects such as JavaScript and CSS.

Google tries to understand things like what your page is about, who created it and who it is for In order to better serve the results that people want. A lot of this semantic analysis is linguistic – interpreting language to understand the meaning, intent and context of a page. At the same time, it identifies and annotates details such as addresses, opening hours and phone numbers.
The index itself is like the index of a book, where each word has a corresponding list of pages it appears on – along with some “per-document meta data.” This massive index is broken up into groups of millions of pages called “Shards” – not to be confused with “sharts”. There are thousands of shards. The index runs continuously and indexes/updates some number of billions of pages per day.
Query processing
After a search query has been entered, Google begins its process to understand and expand upon it. It then retrieves and scores documents, based on a set of principles. It goes a little something like this:
- Does the query name any known entities?
- Are there useful synonyms?
- What is the context?
If you mention a person, a place or a brand name that Google knows, it tries to take this in account. The next step is to compare them to synonyms and determine if there are any useful ones. For example: “coke” might mean “coca-cola”, but it could also mean other things. Lastly, they look at the whole query for context.

After analysis, the query is sent to all of the shards, where each shard finds matching pages, computes a score for each query+page and sends back the top results, which get combined into one list of results, sorted by score. Paul casually drops a bombshell:
“We compute a score for the query and the page. This, computing the score, is the heart of ranking in a lot of ways.”
We’re not quite done, though. At this stage in your search for muffin recipes, there are still post-retrieval adjustments to be made. An algorithmic analysis is performed to look at things such as:
- Host clustering
- Sitelinks
- Is there too much duplication?
- Spam demotions
- Manual actions
How is the query/page score calculated?
It’s based on something called “scoring signals” – similar to the AdWords Quality Score. Some of these signals are universal (based on the features of pages) and others are query-dependent (based on features of both the page and the specific query). These are the examples given in the presentation:
Query independent:
- PageRank (still used internally by Google, though not publicly updated since 2013)
- Language
- Mobile-friendliness
Query dependent:
- Keyword hits
- Synonyms
- Proximity
He mentions that what Google ranking engineers actually do is to write the code that does all this, as well as looking for new signals and combining old signals in new ways. I think it’s safe to say that social signals (likes, shares, etc.) are one of those “new” ones. This all leads us to how they do it, which in turn leads us to metrics.
“If you can not measure it, you can not improve it.” – Lord Kelvin (paraphrased)
What are metrics and how are they implemented? Paul later states that he doesn’t even begin to list all of them here, but there are several key metrics that play a big role:
1. Relevance
As in: does the page actually answer the user’s query in a useful way? Paul states that this is the major metric they look for and talk about internally at Google. It’s actually the one they use to compare themselves to other search engines, i.e. who provides the most relevant results.
2. Quality
How good are the results? Since a page can be relevant to a topic without having good content or provide a good user experience, this metric is almost as important as the first.
3. Speed
Faster really is better. Since it is the third most important metric, perhaps you should take another look at your own technical SEO?
The results are reciprocally ranked, so that the first position is worth 4 times more than the fourth, 10 times more than the tenth, and so on. It is the job of the engineers to optimize these results for their metrics (and vice versa). Since it can’t all be based on what an algorithm thinks, they implement another element.
Live experiments
These are very similar to the types of experiments you might do on a typical website, especially for conversion optimization. It involves things such as A/B testing, click patterns, bounce rates and so on. Paul brings up the example of the blue color that Google uses for its links and highlights – they tried 41 different shades of blue to determine if it changed user behavior.
“It is very rare if you do a search on Google and you’re not in at least one experiment.”
Human rater experiments
This step involves having people evaluate various search engine results pages, based on Google’s guidelines. Thankfully for us who are interested in SEO, these guidelines have actually been publicly published. You can find them here. It is recommended reading for anyone who wants to improve their site.
“If you’re wondering why Google is doing something, often the answer is to make it look more like what the rater guidelines say.”
Human raters get two sliding scales that range from 1 to 5, which are used to rate results – but it’s a variable scale without steps, so the rating can also land anywhere between two numbers. It is well worth reiterating that they focus on mobile user needs when it comes to both metrics.
- They use more mobile queries than desktop queries in human rater experiments.
- They pay close attention to the user’s location.
- They have special tools to display mobile user experience
- Raters often visit websites on smartphones
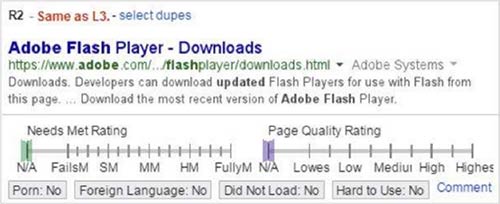
The first slider is for “Needs met”, which ponders: Does the page address the user’s needs? It is their current relevance metric. For example, you search for “cnn” and the first result is CNN.com. That is very likely to be what you were looking for. For certain queries, it gets much more tricky.
A person searching for the name of a store might be looking for their website, their closest location or the Wikipedia article about them – this is where the human input is especially helpful. Which one should they show; one, two or all of the options?
The second slider is for “Page quality”, which simply asks: How good is the page? That includes if it is easy to navigate, if it looks professional, if the author is an expert on the subject, if it loads quickly, etc. It can be very subjective, which is exactly why the guidelines play a big part.
High quality indicators:
- It has a satisfying amount of high quality material
- The page and website are authoritative and trustworthy for the topic of the page
- The author has expertise on the topic of the page
- The website has a good reputation for the topic of the page
Low quality pages:
- The quality of the main content is low
- There is an unsatisfying amount of main content
- The author does not have expertise, trust or authority for the topic
- The website has a negative reputation
- The secondary content (such as ads) is distracting or unhelpful (too unrelated)
How does topic trust work?
One way to look at it is to imagine you have a popular blog about fashion. Every post you make is about fashion and its related subjects, and all of the links you get are from similarly themed sites. This builds both trust and authority for you and your site when it comes to fashion – but not much else.
If you make a single post about something completely different, say you buy a new TV and decide to review it. That post is not likely to rank well for searches related to TVs, despite the fact that your site has a high level of authority and trust, simply because the topic is different. This is why relevance is just as important as trust and quality.
Optimizing for metrics
After the human raters have completed their tasks, all of their ratings are aggregated and sent back to the ranking engineers, which is a team of a few hundred computer scientists. They focus on the metrics and signals, they run a lot of experiments and they make a lot of changes.
The development process:
- Idea
- Write code
- Generate data
- Run experiments
- Analyze data
- Report
- Review
- Repeat
The goal is, obviously, to receive higher and higher ratings from the human raters. This means altering the algorithm, so that it moves results with good ratings up and moves results with bad ratings down. This doesn’t always work out as planned. There are two major types of problems: Systematically bad ratings and metrics that don’t capture the most important things.

As an example, Paul uses a search for a brand of fertilizer. It is likely that user is interested in buying some of this fertilizer, but the results page showed a map of the manufacturer’s headquarters. Since this was seen in the rater’s eyes as very relevant, it was rated as “highly meeting” their needs.
This means that they need to add a step to actually review the results of both live and human rating experiments, to look for things that might be bad – Then create new examples to test for those types of “errors.” Updating the guidelines, developing new metrics and learning more about the user’s intent are all key factors.

Paul brings up the emergence of content farms during 2008-2011, which would push out massive amounts of low-quality, but very relevant content in order to game the search engine. It worked – REALLY well. Their human raters would rate the content as highly relevant, and that type of content would keep rising to the top. This led directly to inventing the “quality” metric previously discussed.
“We thought we were doing great, our numbers were saying we were doing great – and we were delivering a terrible user experience.”
So, there you have it. A (fairly) comprehensive explanation of how Google works in general. This doesn’t go in to much technical detail, since it was a mere 30-minute talk in front of an audience, but I will delve a little bit deeper in to the mind of Google. Let’s start with some key points from the Q&A that followed Paul’s presentation, featuring both Gary Illyes (Webmaster Trends Analyst) and Paul Haahr. Watch it here:
Being logged in makes a big difference
All of your interests, habits and favorite websites play a part in your search experience – And it’s not device-specific. Google will collect information about you in order to serve you more (personally) relevant results. Paul points out that all of the personalized features were put in there to make you feel good, like Google is helping you, not to creep you out.

For example, if you are programmer and you search for “python”, it is much more likely that you are looking for sites related to the programming language than the type of snake. It is also more likely that you are looking for the company when searching for “apple”, rather than the fruit. The results might be reversed if you are interested in animals and healthy eating.
Human raters may have a brand familiarity bias
Many people who work in SEO and SEM have muttered about how Google tends to favor big brands. One of the questions asks how they counter brand bias from human raters, since expertise can be much greater in specialized sites. Paul says that they ask the raters to do research, and that they have other metrics to try to counter that bias. Draw your own conclusions, but it sounds to me like the little guy will have a harder time in general.
Click-through-rate is (at least) an indirect ranking factor
He seems hesitant to give a direct answer to whether CTR has an impact on rankings or not. It is definitely used in live experiments and for personalization – for example, to see if including sitelinks improve the click-through-rate.
Positions matter
This is no shocker. Position 1 gets the most clicks, 2 gets the second most, etc. However, it’s interesting to note that position 10 gets more clicks than 8 and 9 put together, because it’s the last one before you have to go to the next page – which no one wants to do – but position 7 still gets more clicks than 10.

Takeaways for search engine optimization
There are a number of things to consider when optimizing your website. In order to maximize visibility, you should at least:
- Make sure your site is mobile-friendly
- Make sure your site is user-friendly
- Make sure your site is technically optimized (for speed)
- Use correct markup in your content and ensure that it works with “features”
- Use plenty of synonyms and variations in your content
- Follow Google’s guidelines (mostly)
Hopefully you learned something today. We certainly found it interesting!
Part 2: How does Google RankBrain work?
